Linguistics & MLPs & Shenanigans
NOTES:
- This post is a work-in-progress. I wanted to get my thoughts down before forgetting them, but I am planning on reworking it later.
- If you notice any issues or misunderstandings I have, please contact me by email at elkhouriela@gmail.com
Background
I'm quite new to ML. And by new, I do not mean "have taken a few courses, have done a few projects"-- I am new in the sense of utterly tyronic. The first few lectures of CMU's wonderful 11-785 and my base of tech-related general knowledge kept me afloat throughout this adventure, though obviously I'm going to be upgrading from my little knowledge raft to a very sophisticated, rickety sailboat as I learn more.
Despite this, I've never been one to shy away from ambitious projects. I set my sights on making [something something] Minecraft. I figured that the [something something] would fill itself in later, as [something something]s tend to do.
But I knew I couldn't just dive into that, at least not without sharpening my teeth on another problem first. The idea was simmering, yes, but my Davis-ite ooga booga nature compels me to at least try to build things from scratch before enjoying the luxury of abstractions.
I built a small, mostly-functional MLP in CPP. After using that for simple French vs German binary classification, I moved on to implementing the actual meat of my project in Python. I am planning to go back to my CPP library impl after I have better intuition, since I genuinely did enjoy messing with that, even if it was a little painful sometimes... anyway, I'll get on with it.
Classification & Analysis
This blog post is not about milking language classification accuracy-- not included here is my training of a more "normal" network that works quite well, with more language classes than I mess with here. This is mostly just an account of my network structure analysis escapades that have a slight linguistics tinge :)
Of all this deep learning business, the topic that piqued my attention the most is network architecture. I've come to understand that modern language modelling is, for the most part, feeding data into a behemoth of a black box and trying to coax some useful information out.
I won't say that this concept doesn't excite me-- it very much does!-- but I enjoy trying to make sense of my systems work the way they do, and thus wanted to design my language classification model to be studyable. I landed on purposefully bottlenecking the penultimate layer of my network; basically, I forced it to have approximately the same amount of neurons as my corpus had families, with some extra nodes for "tolerance."
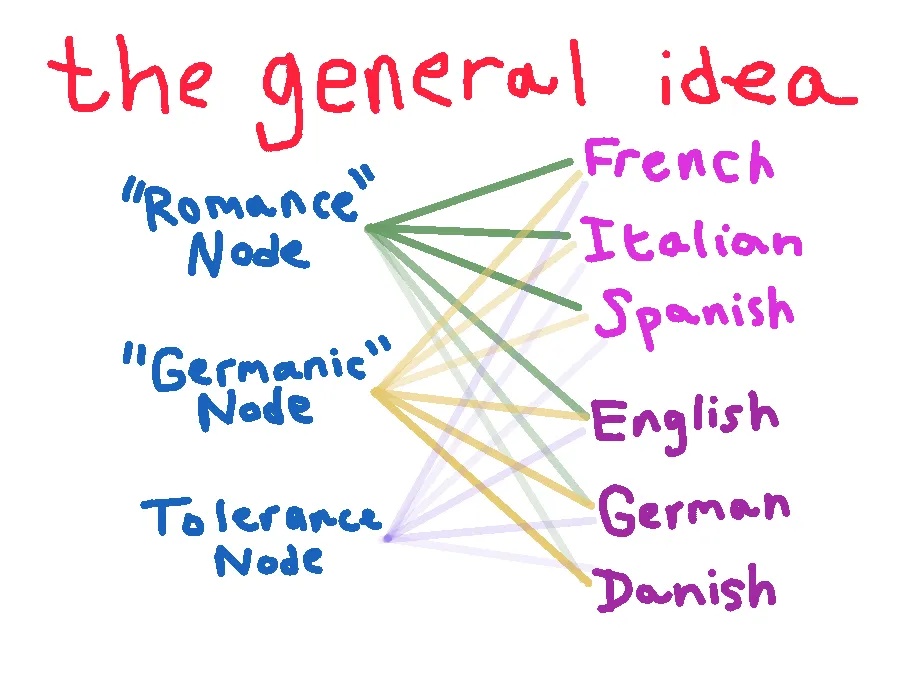
But what even is "tolerance" here? Language families are not strict things, and cultural exchange has led to Germanic languages like English having vocabularies that are 60% or more Romance-derived.

I hypothesized that adding extra nodes that could proxy some discrete patterns would alleviate some of the issues that came with the bottleneck. For example, French and English share a lot of vocabulary that wouldn't necessarily be explained by modelling English as some 60:40 combination of Romance:Germanic vocabulary, because the relation that is shared between them is a direct transfer of French -> English, not the progenitor-descendant evolution we are set to model. You can thank William the Conqueror for this conundrum.
Approach Issues
Before running anything, I tried to predict how my model would behave. I knew from the get-go that
- There will likely be granularity issues within language families
- If the model is small, we will need significantly more tolerance nodes, as a larger model will use the other "language families" that may or may not have linguistic significance to optimize for classification accuracy
- Since the only input features are ngram frequency, we lose information about... well, basically everything that isn't syntactical
Simplified Sims
To demonstrate these things, let's see what actually happens when we try to classify with the sort of model I drew in "the general idea" drawing, with and without the tolerance node. Do pardon the visuals... still not sure how to properly get this stuff across :)
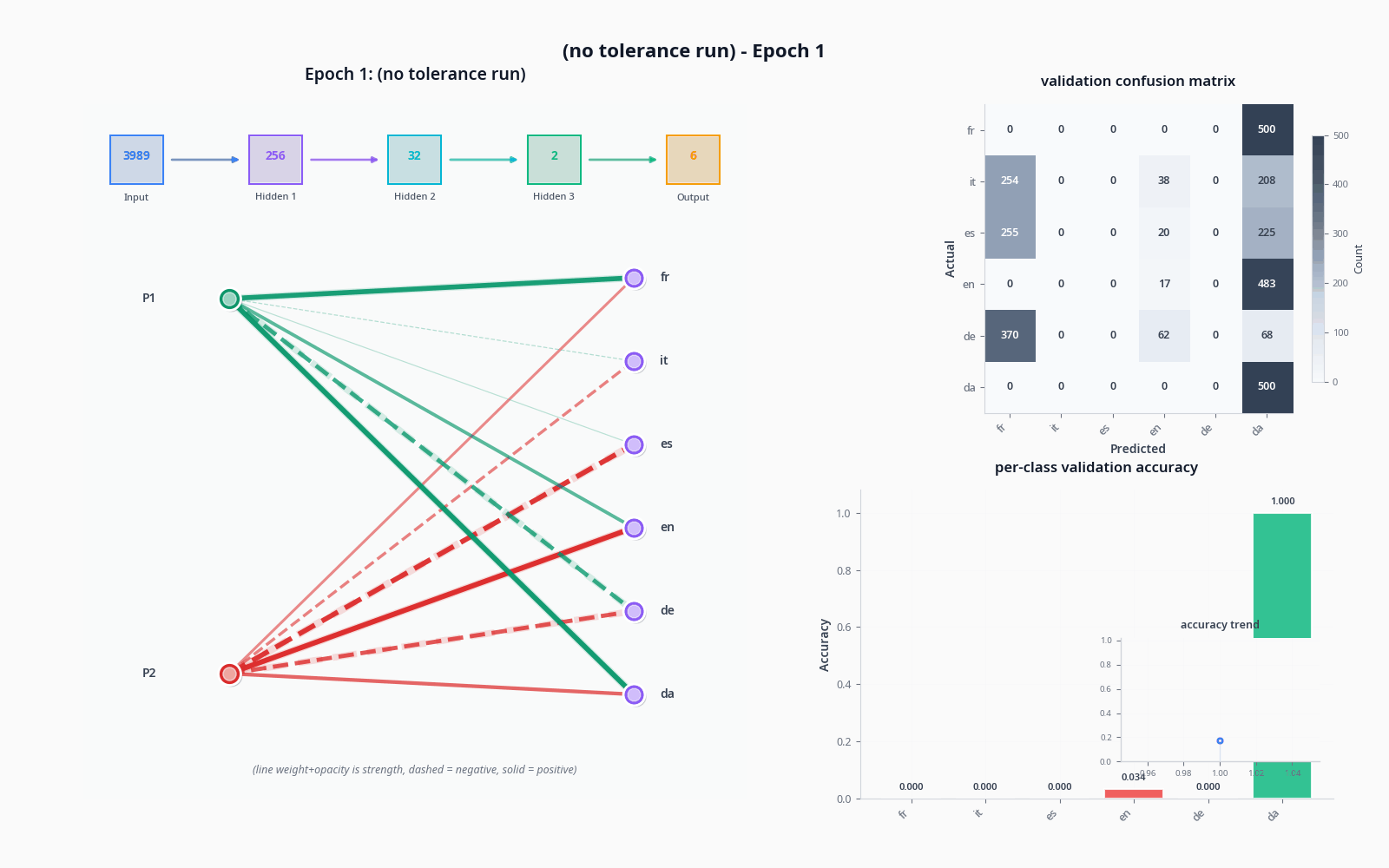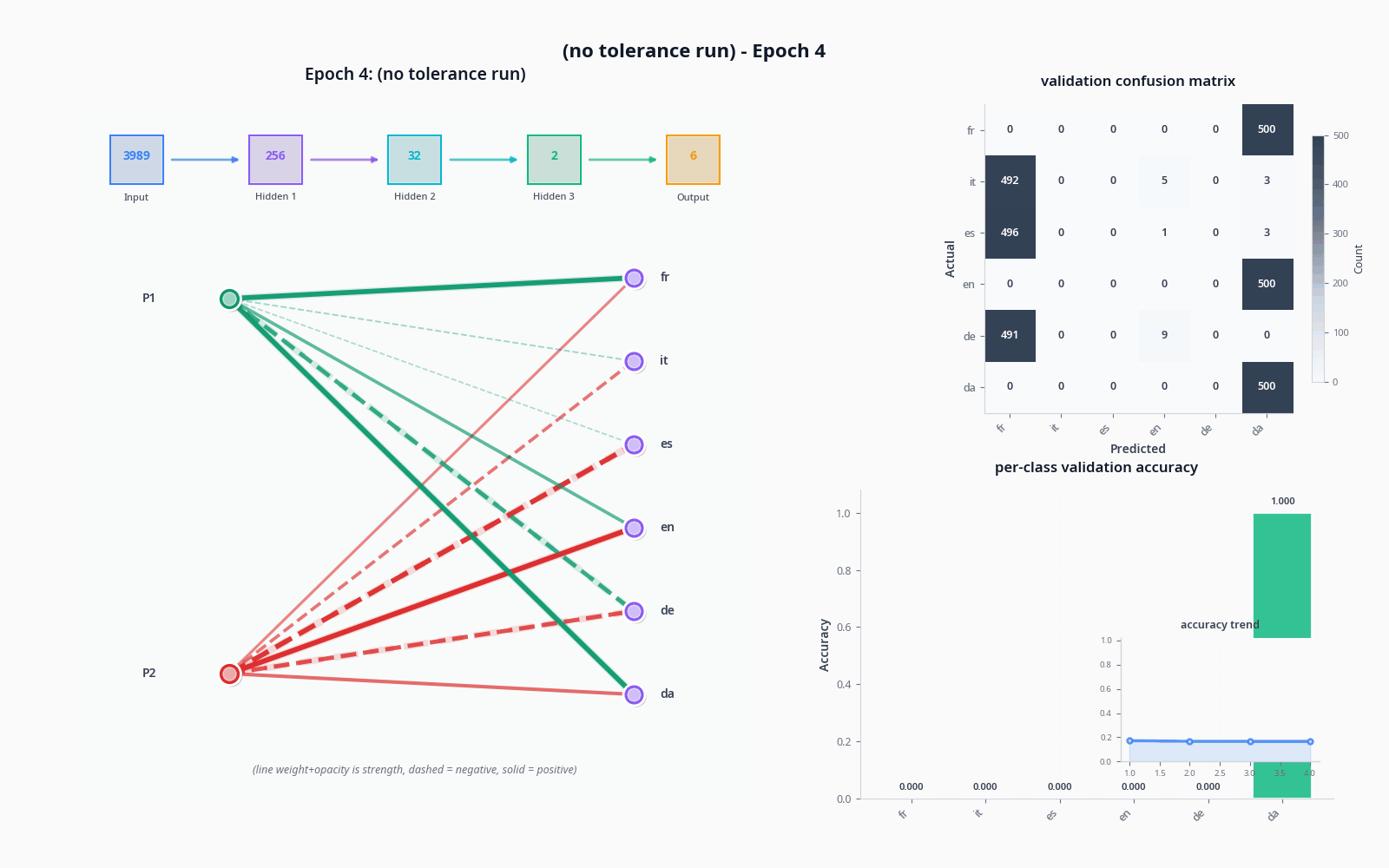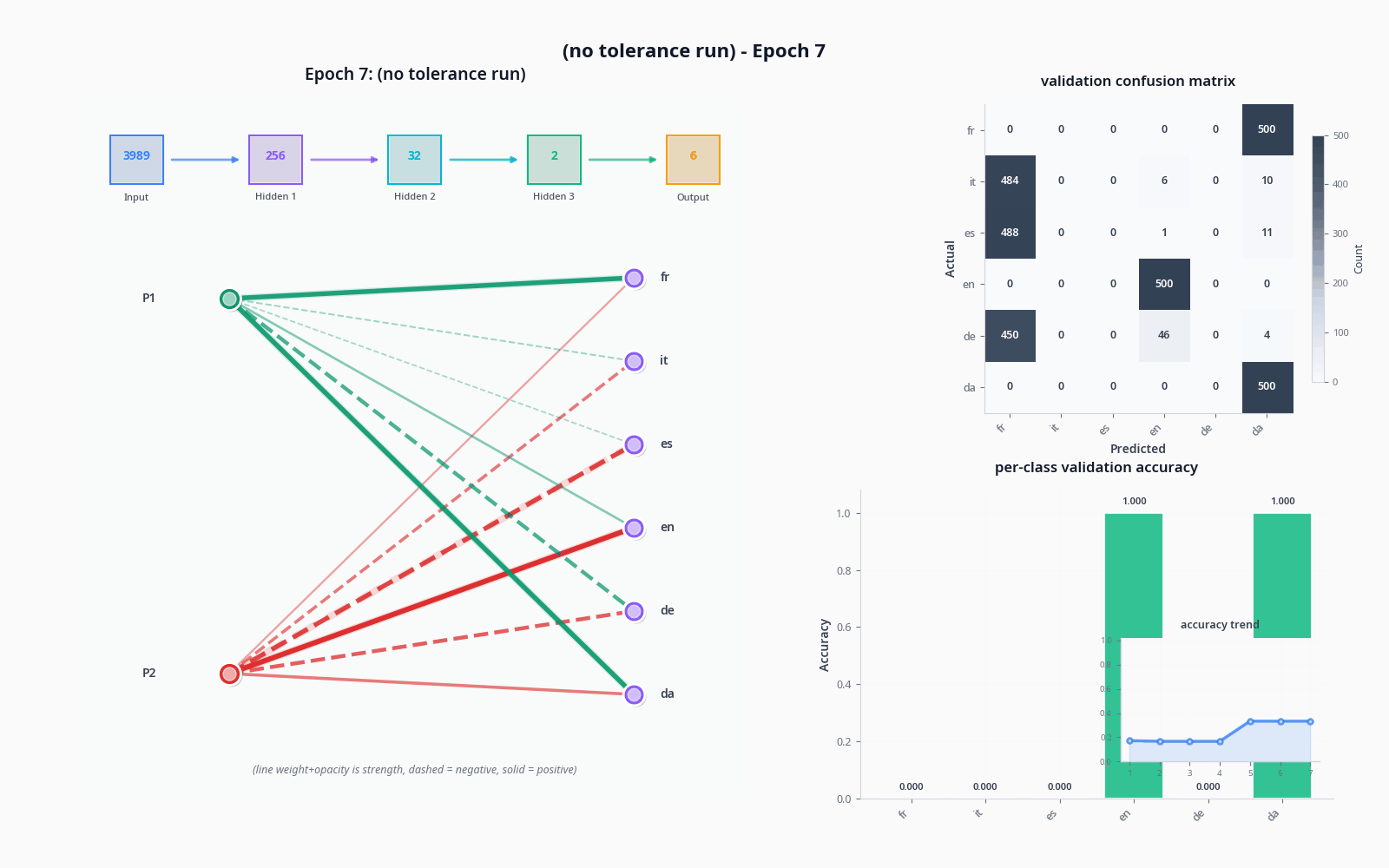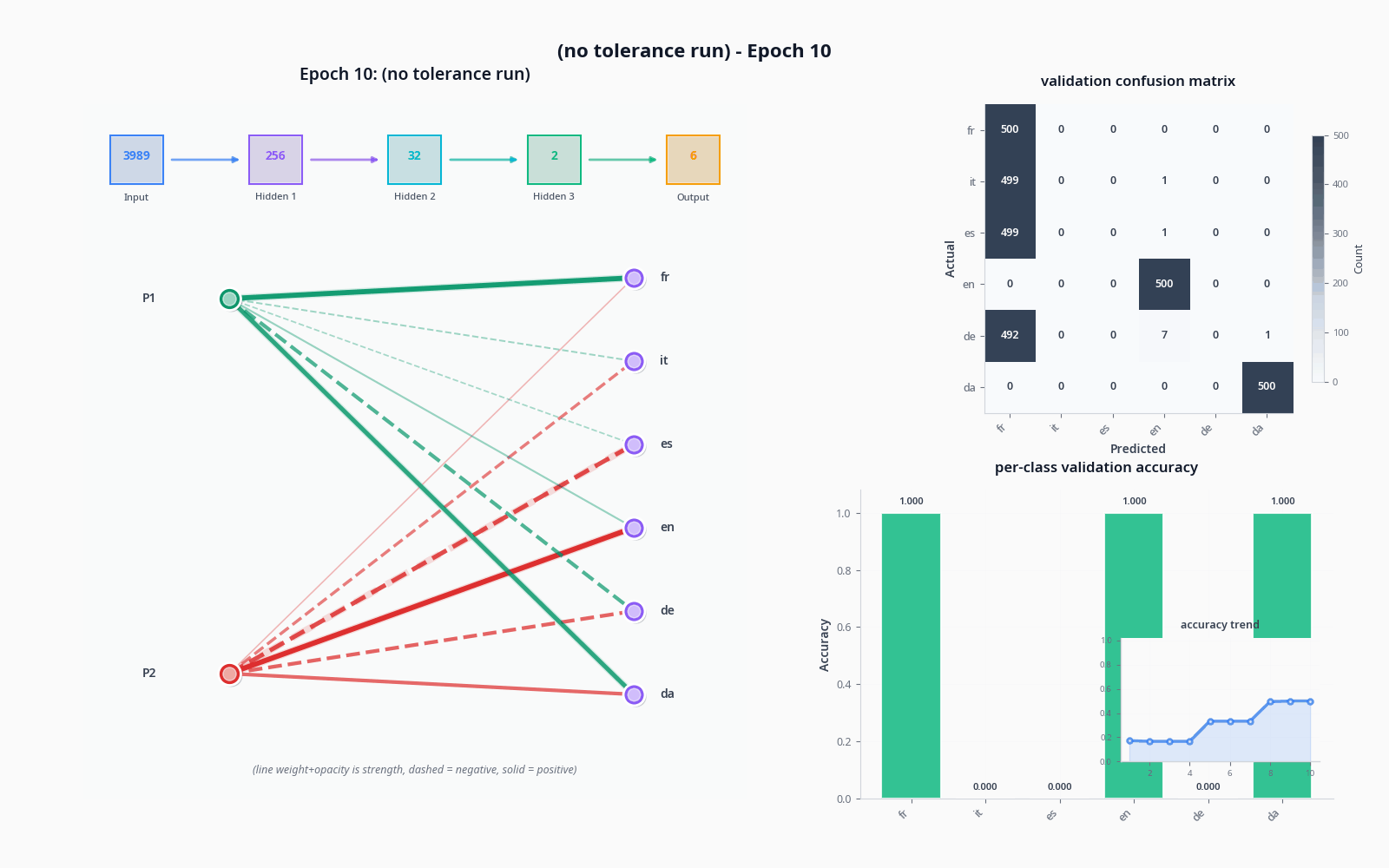
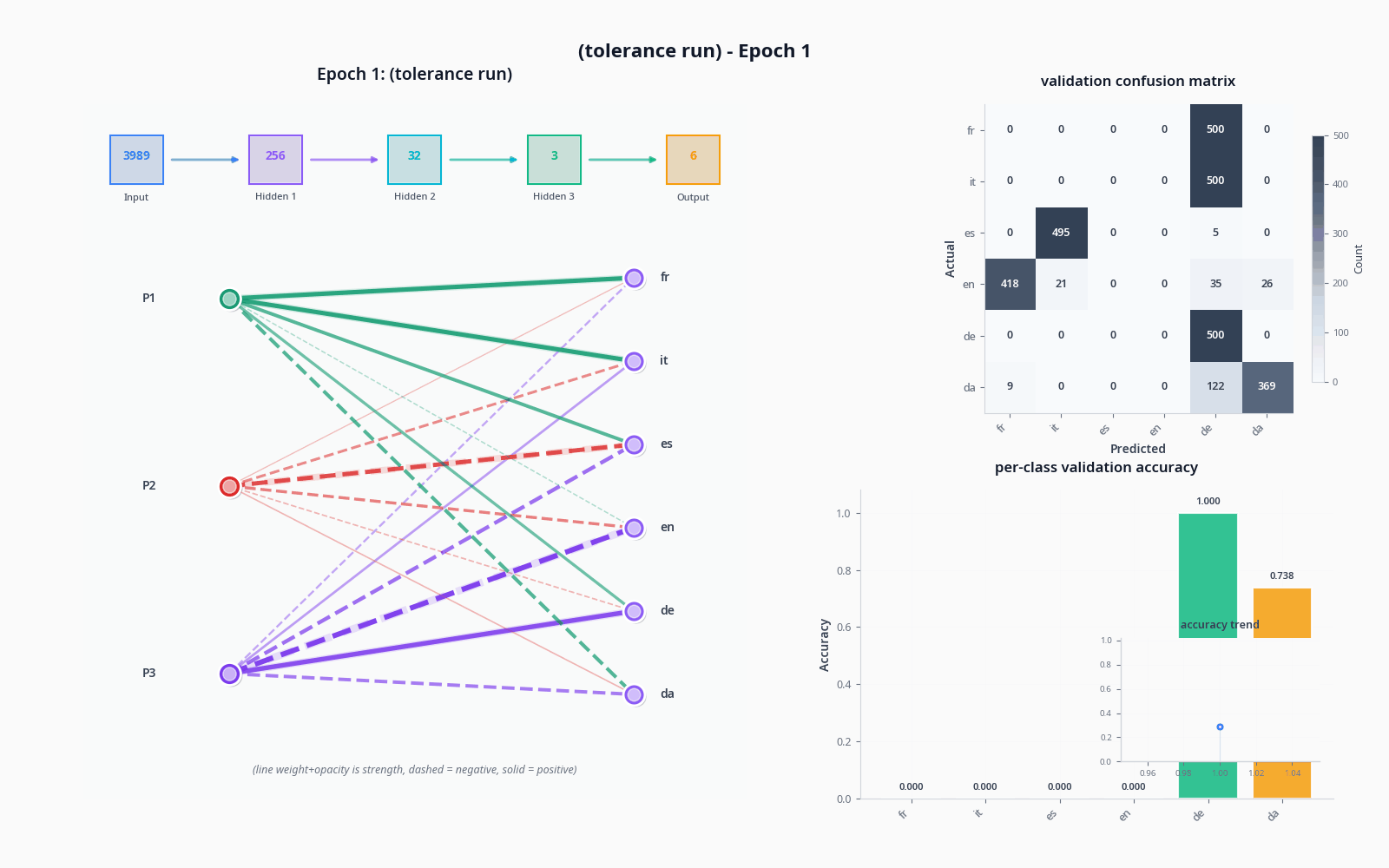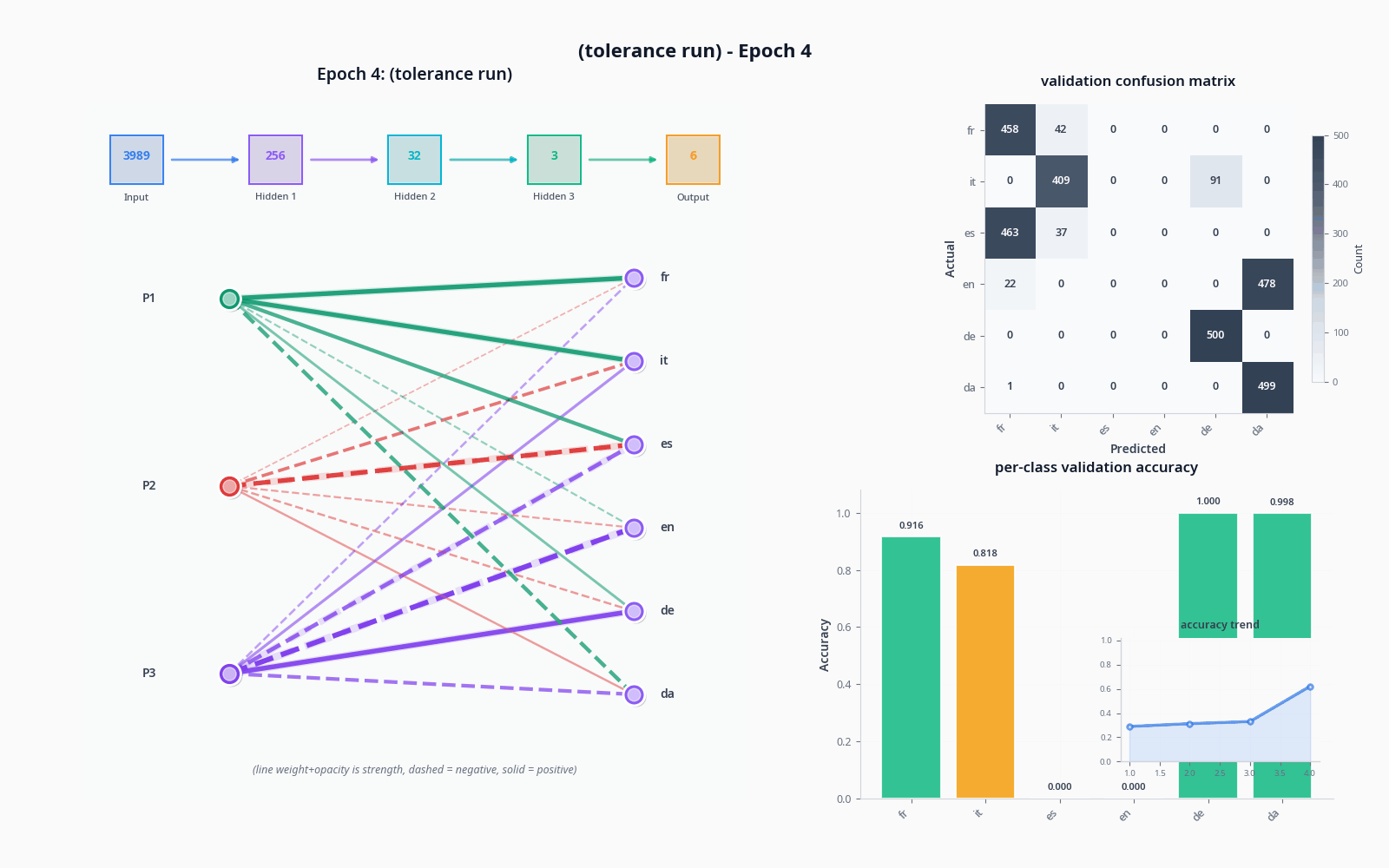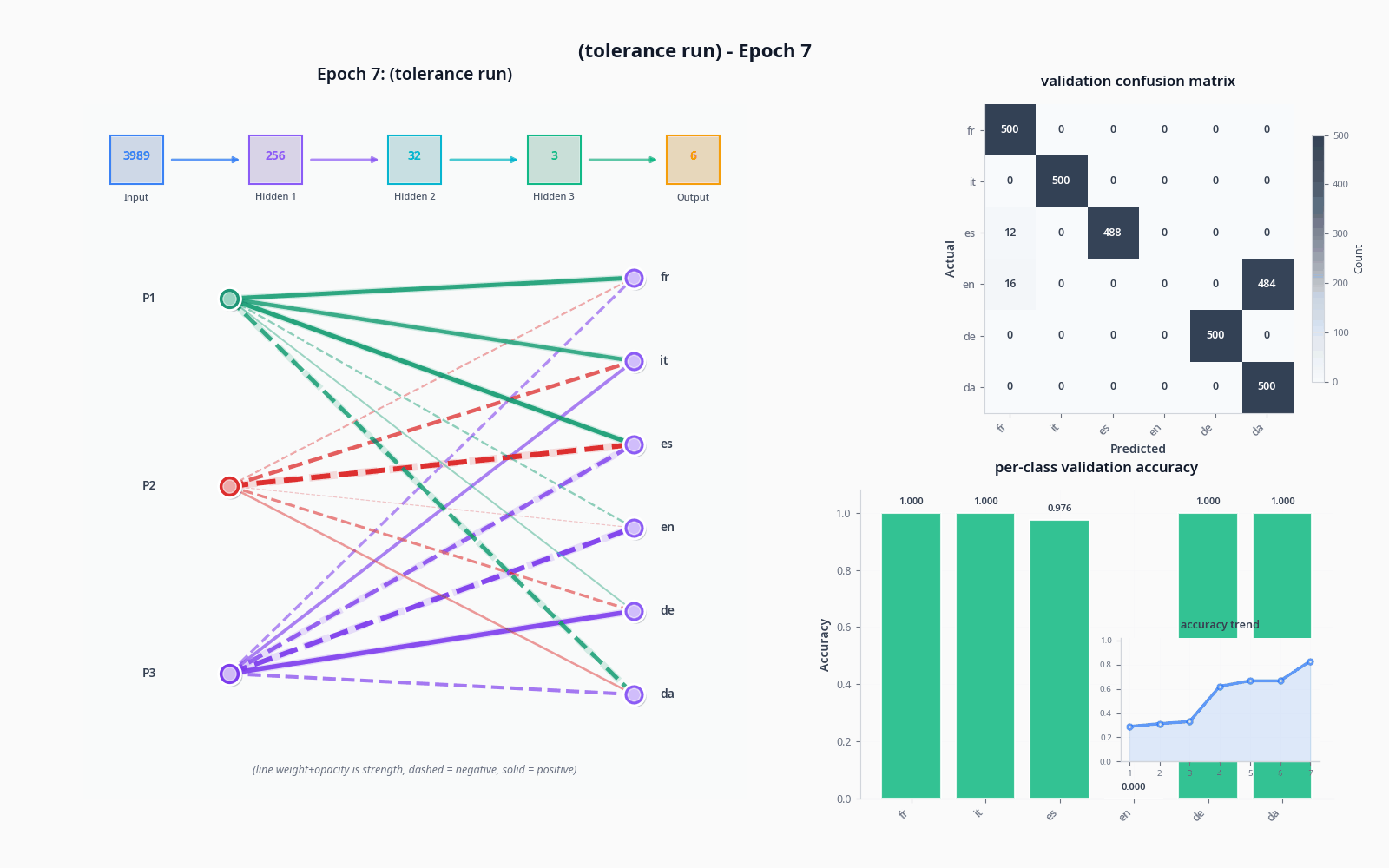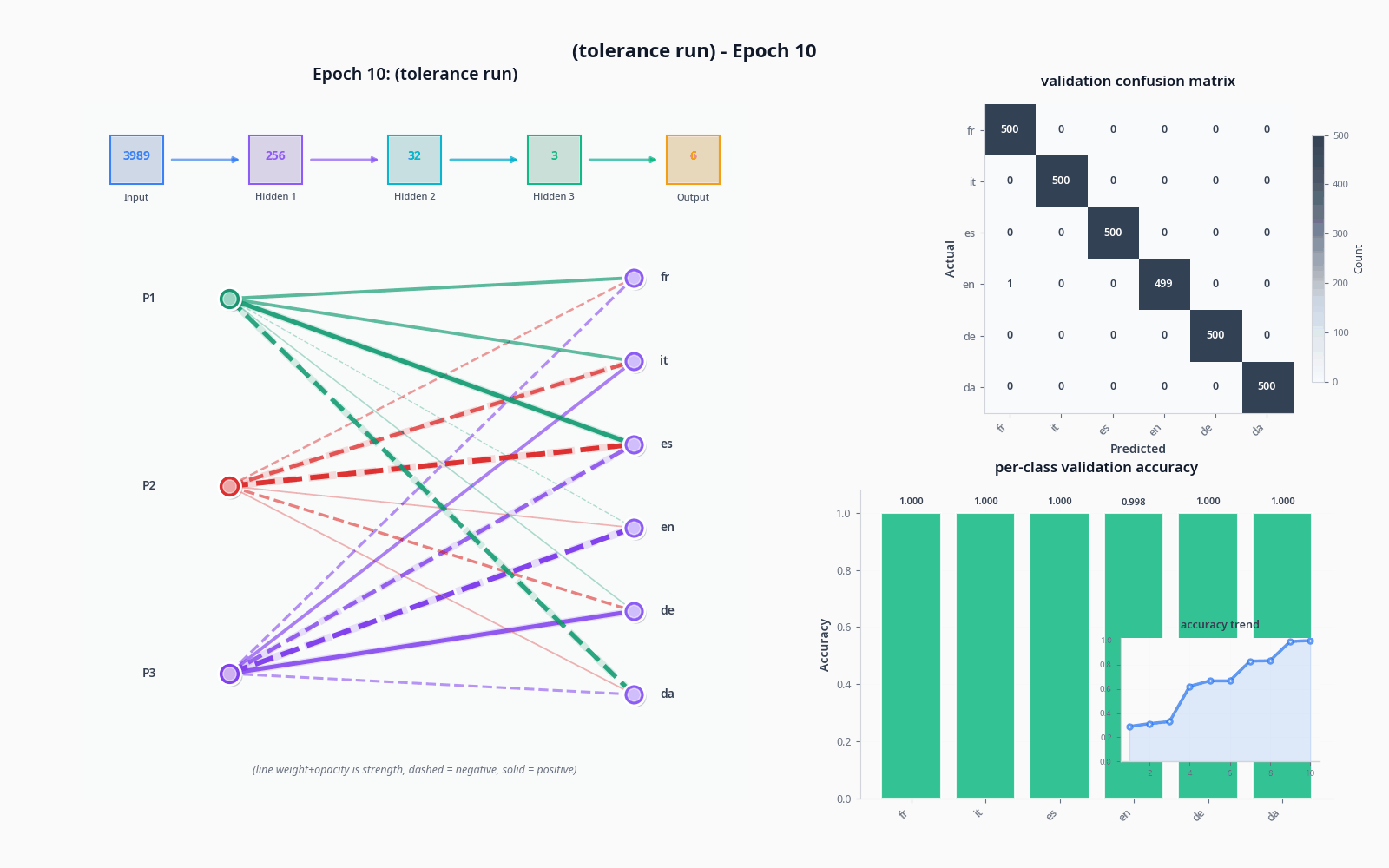
I used the OPUS-100 dataset (not what I trained on) and sampled 1000 texts per language to get realistic accuracy values.
| accuracy (%) | |
|---|---|
| 2 | 48.82 |
| 3 | 93.87 |
The improvement was quite dramatic, but not necessarily proof of tolerance doing much on its own-- a two-node penultimate layer will lead to training collapse pretty often. A sufficiently large model will not see a dramatic increase like this from adding an extra node, and I suspect it could potentially lead to issues depending on the base of languages being pulled from (I'd like to simulate this, but my computer is sadly too slow).
I did get an interesting result with a 4 language family dataset (Romance, Germanic, Slavic, Uralic), but it could very much be a fluke + Uralic's dissimilarity could possibly be driving this-- the accuracy drop comes from the complete training collapse of Portuguese.
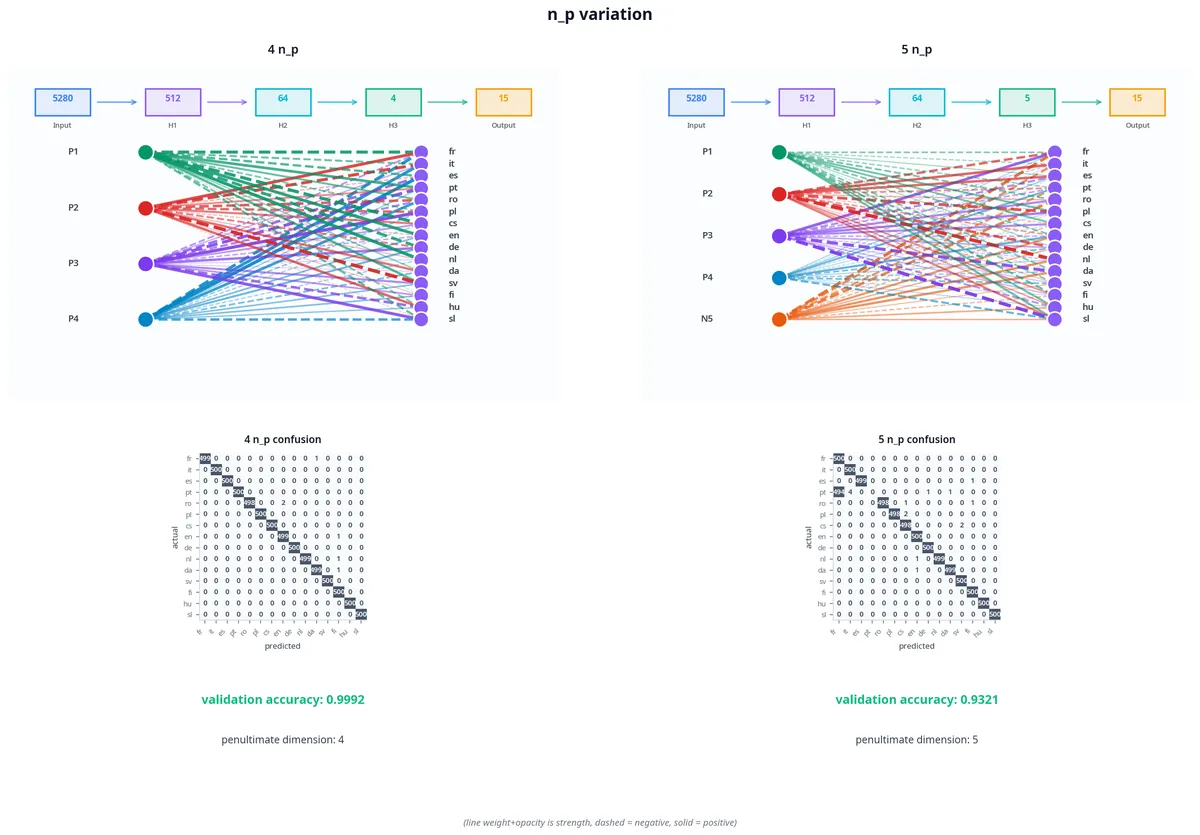
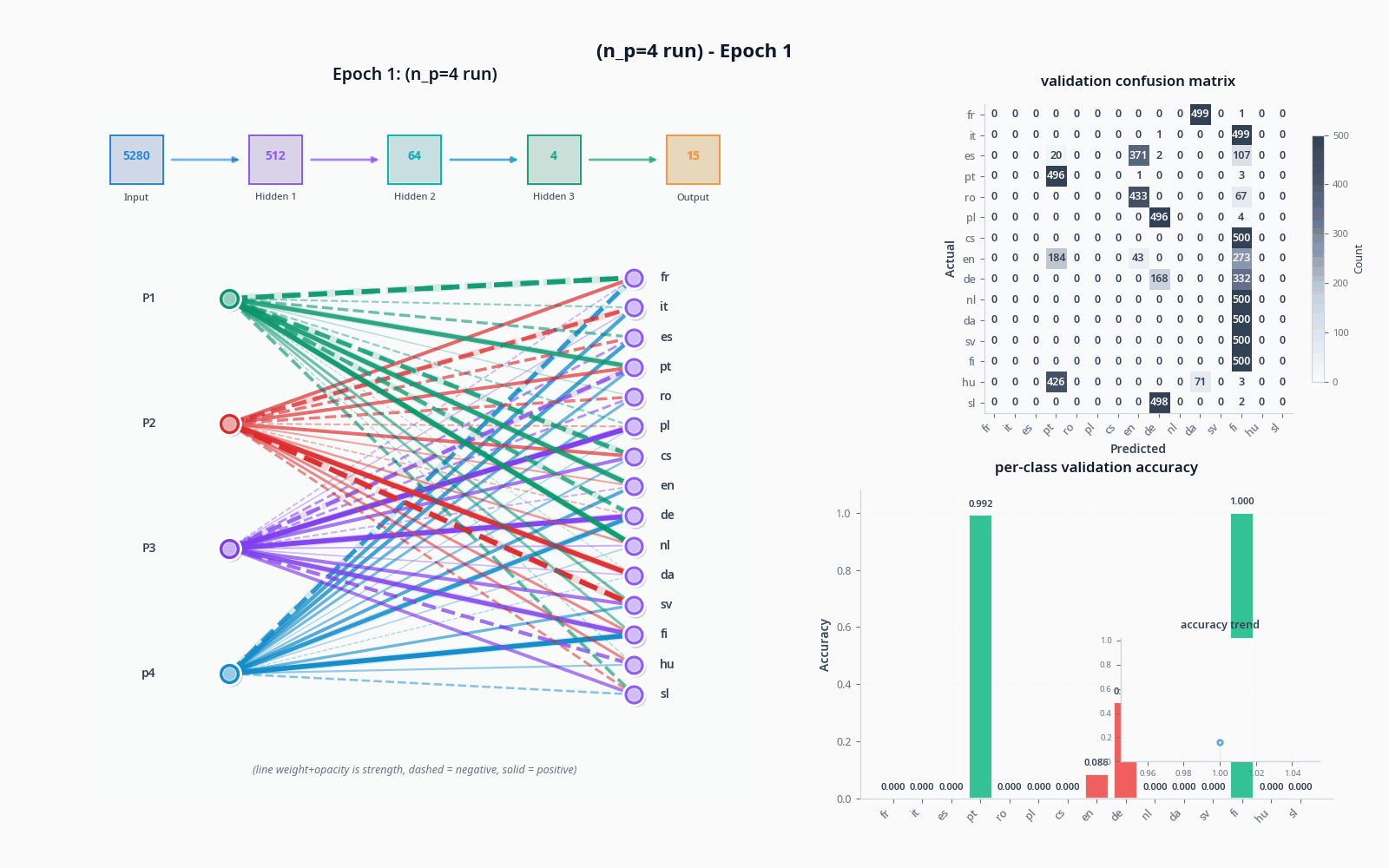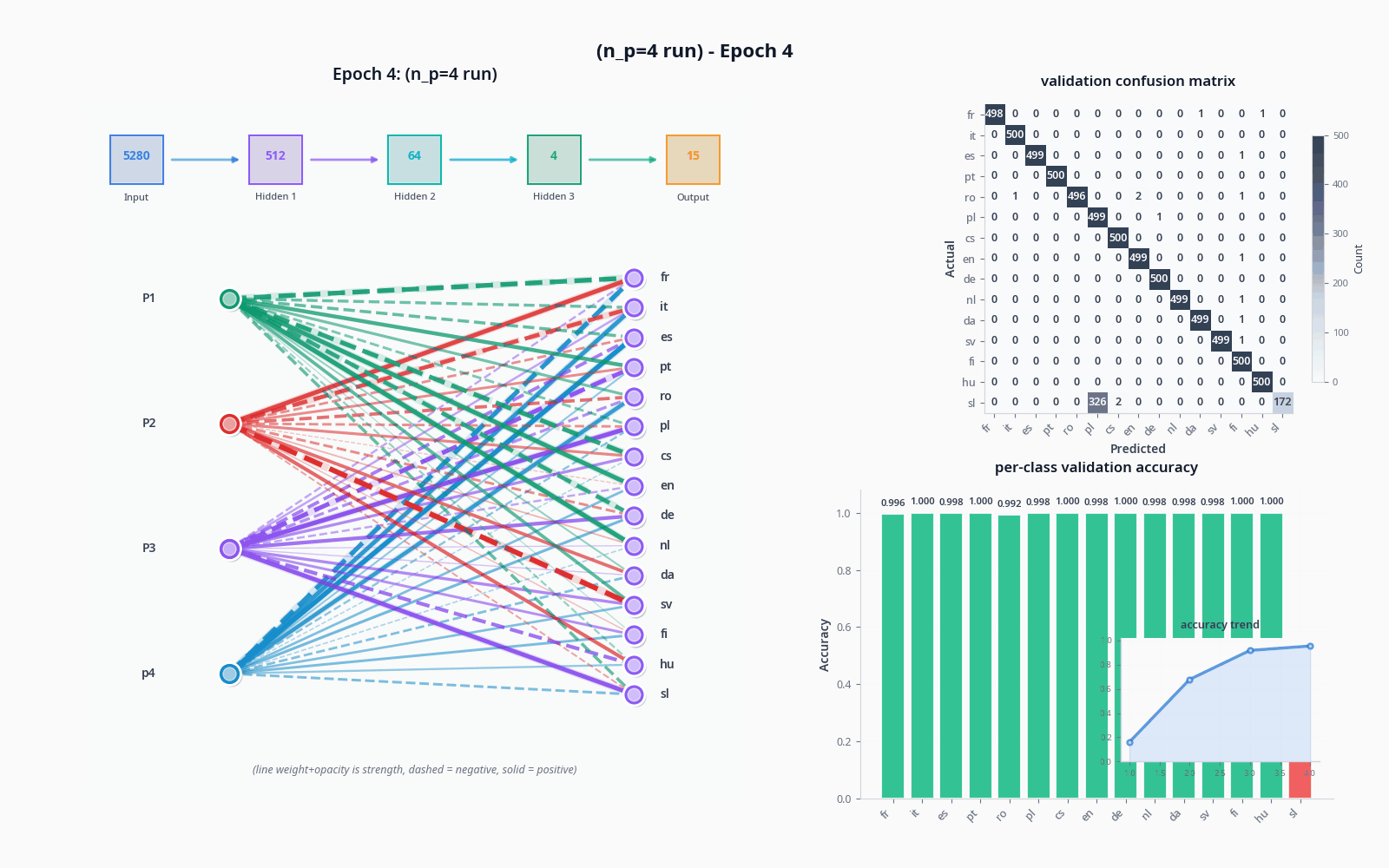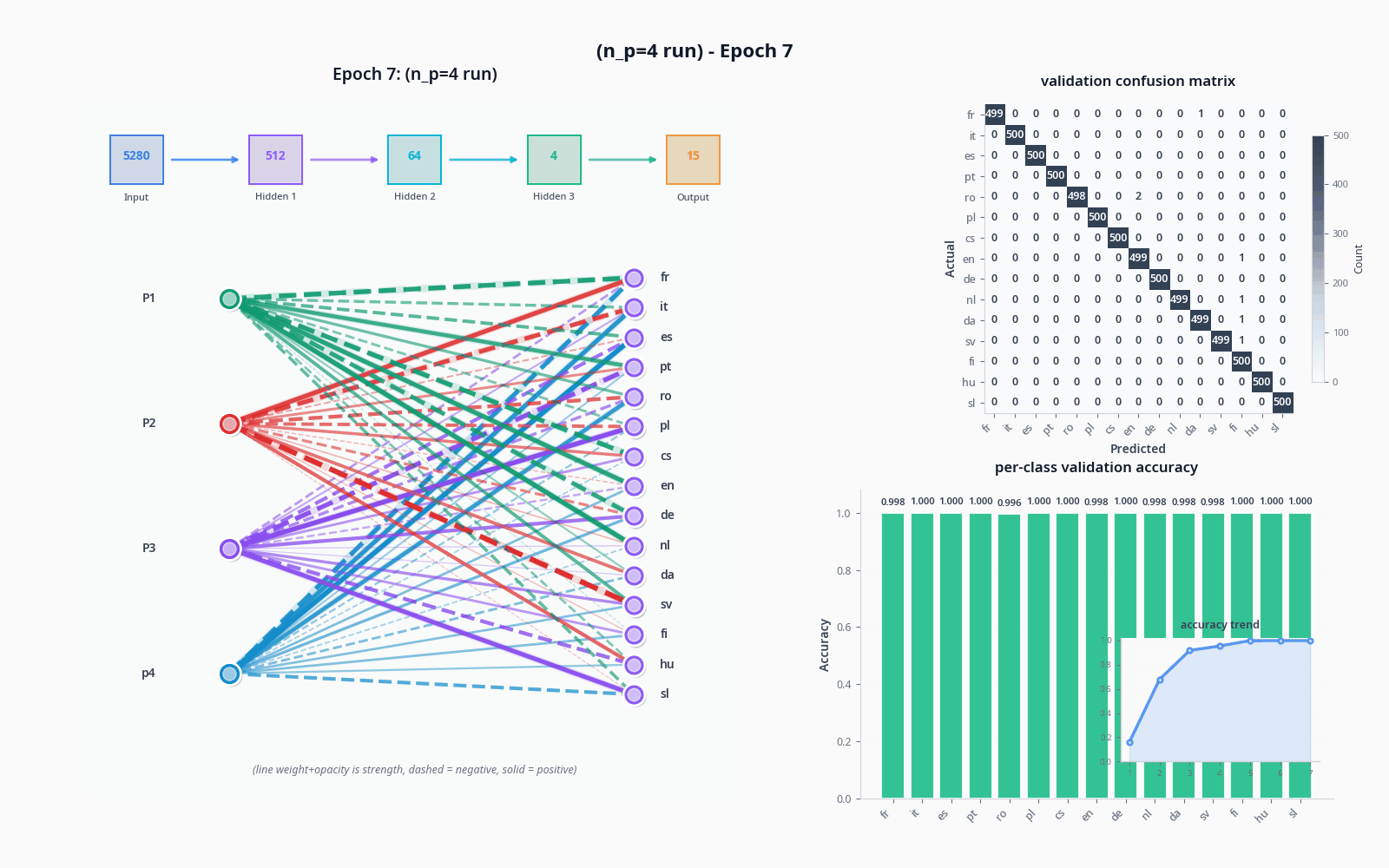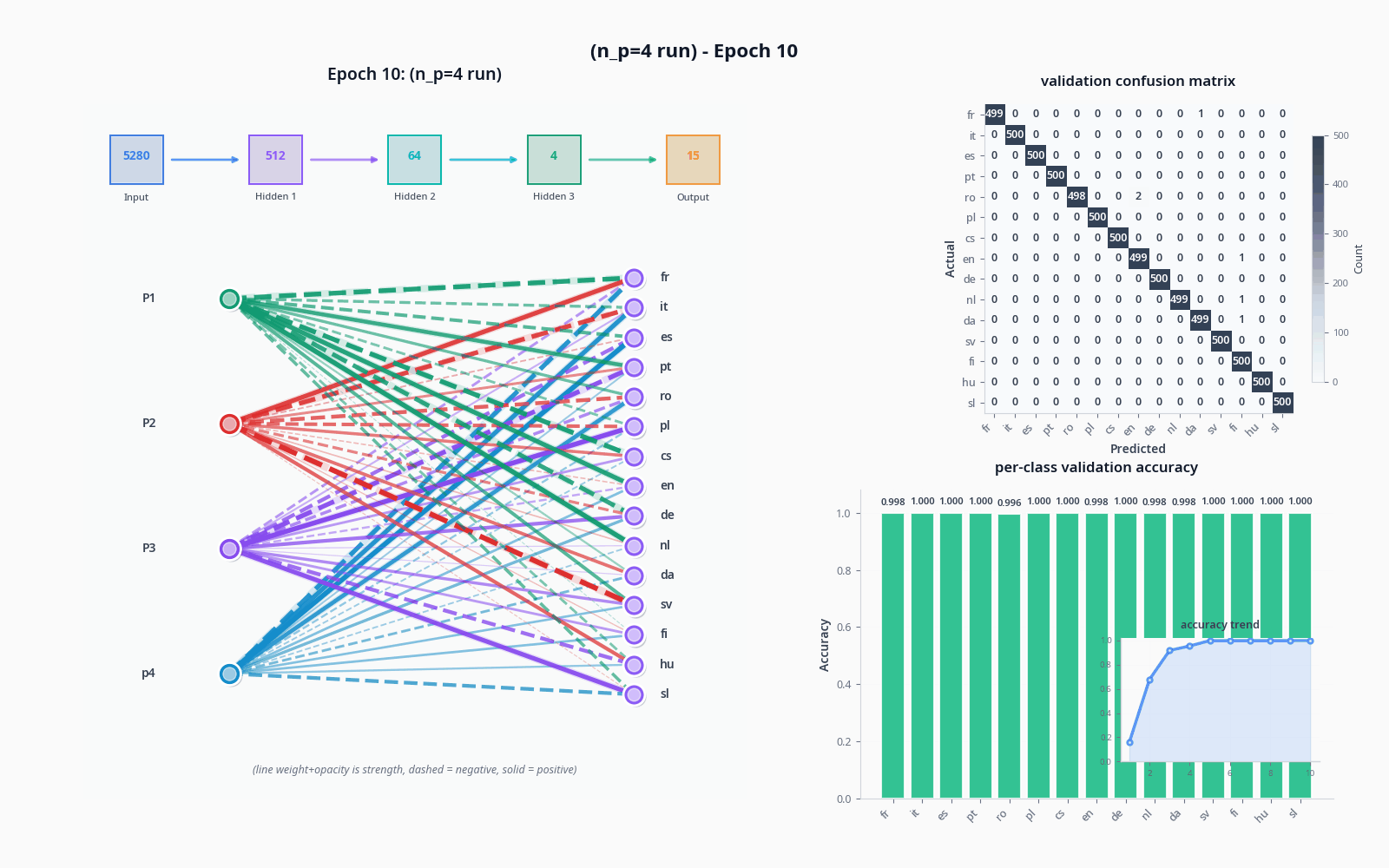
| accuracy (%) | |
|---|---|
| 4 | 84.48 |
| 5 | 77.57 |
| 6 | 90.51 |
I will be looking into ways to prove or disprove the null hypothesis soon, and if I can secure enough compute I'll try to run a larger-scale eval on this stuff.
Training with more languages
Just for fun, I grabbed a dataset of a few hundred languages and trained on them. To account for script differences, I added some miscellaneous features like Unicode block distribution. This approach was actually pretty successful! Well, kind of.
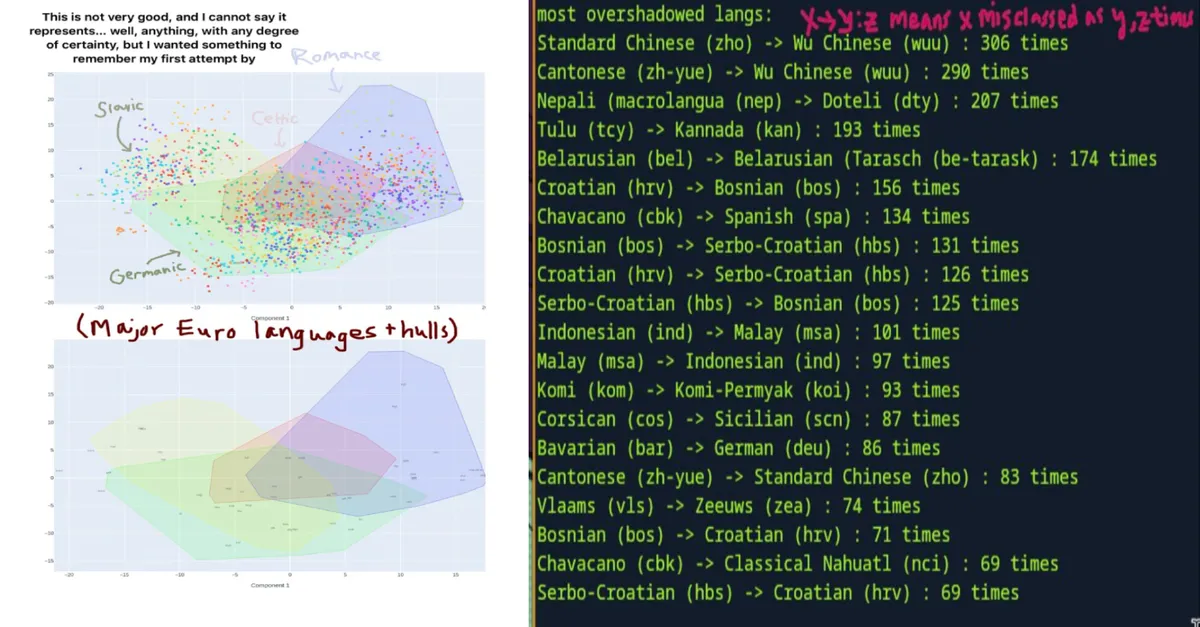
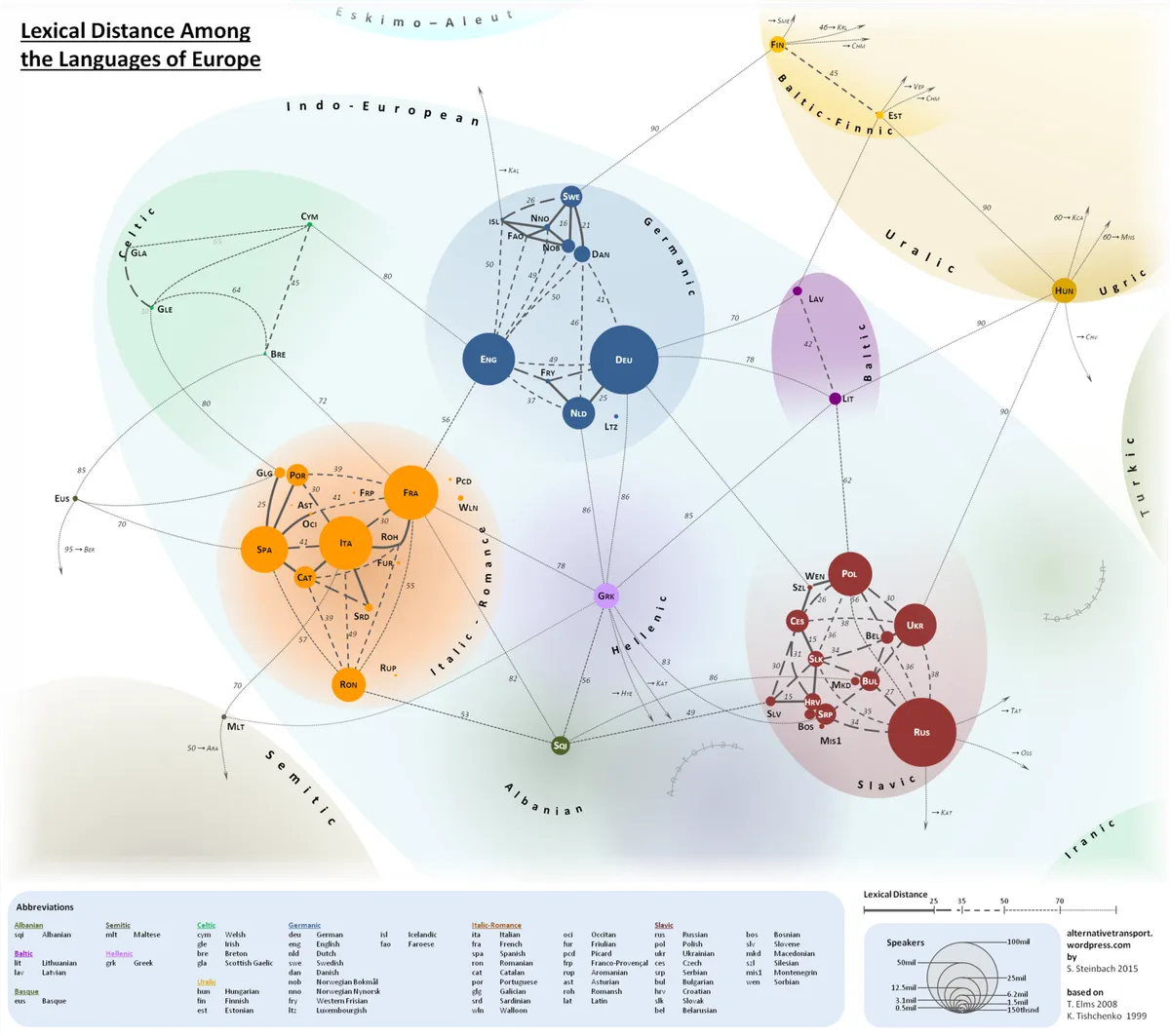
As I predicted before, confusion between similar languages is very much prevalent. The disproportionate representation of Balkan languages as "most confused" is no mistake; they are reproducably so close to each other that many people consider them to be one language. On the graph below, you can see European language lexical distances. HRV (Croatian) sits abreast SRP (Serbian), with their sisters BOS (Bosnian) and MIS1 (Montenegrin) touching them as well.
What gives for the rest, though? Standard Chinese seems like something that should not be misclassified 306/500 (61.2%!) of the time with Wu (Shanghainese).
The issue here lies in how we tokenize text. I chose an even distribution of samples from every language, so Chinese characters are very rarely actually processed as features. Zero Chinese characters appeared in the ngram dictionary at all. As far as I can tell, this led to a heavy over-reliance on the Unicode block data I was feeding in.
This phenomenon also explains how some of the high accuracy languages perform so well-- many either have their own script or are particularly abusive of certain diacritics that fall in specific Unicode blocks.
| Language | Code | Acc | Score |
|---|---|---|---|
| Tibetan | bod | 99.8 | 499/500 |
| Hebrew | heb | 99.8 | 499/500 |
| Dhivehi | div | 99.8 | 499/500 |
| Navajo | nav | 99.8 | 499/500 |
| Kabardian | kbd | 99.8 | 499/500 |
| Waray | war | 99.6 | 498/500 |
| Minangkabau | min | 99.4 | 497/500 |
| Central Kurdish | ckb | 99.4 | 497/500 |
| Burmese | mya | 99.2 | 496/500 |
| Chechen | che | 99.2 | 496/500 |
It's certainly the case for the top three, at least.

The strong signals from the next three are rooted in ngrams. Navajo's diacritic frequency dwarfs any other language in our sample-- just the combination '́í' has a presence of 99.6%, which is 8829x more frequent than the mean and 34x more than second-placer Langala.
NAV: Háíshį́į́ naa ntsékees!
ENG: Someone is thinking of you
I will stop here, half because I think you get the point and half because if I don't make myself stop I will go on about language quirks for days on end. So... bye! Not really sure how to sign off lol